Evaluation
Table of Contents
Overview
Participants will apply their system’s inference to open test set during the development phase of the challenge, and to the withheld (blind) test set during the test phase. The participants will submit the processed stimuli for evaluations. To evaluate the performance of the neural speech codec submissions, in the development phase: objective metrics will be used (and provided as a guide only), while in the test phase: crowdsourced listening tests will be used (and utilized for entry ranking). Objective metrics won’t be reported on the blind test set. Please refer to the Official Rules: https://lrac.short.gy/rules for further details.
The crowdsourced listening test battery focuses on assessing transparency, intelligibility, and noise/reverb robustness, and includes:
-
Quality of clean speech (MUSHRA-style evaluation, one system at a time)
-
Track 1: degradation in real-world conditions (DMOS)
-
Track 2: quality of enhanced speech (MOS)
-
Speech intelligibility (DRT)
Test Materials
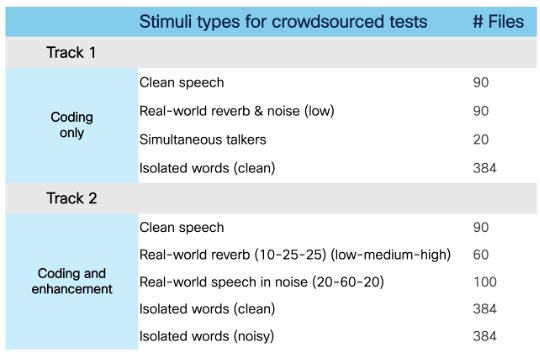
Figure 1: Test Materials
Test materials will include curated test sets focused on quality assessment under clean, noisy and reverberant conditions. Following the conclusion of the challenge, these test sets will be released publicly for the benefit of the research community. For crowdsourced assessment of intelligibility, previously reported approach along with publicly released stimuli link will be utilized.
Objective Evaluation
We evaluated multiple neural audio codecs over 100 clean audio files from a test set. For each codec, we conducted a MUSHRA listening test. A single codec (along with a clean reference and an Opus 6 kbps anchor) was evaluated at a time. The results of tests for all codecs were combined. Pearson correlations were calculated between the subjective scores and objective metrics. The metrics with the highest correlations are shown in the table below. We use the Versa toolkit to compute the metrics and the metric names in the table are taken from Versa documentation.
| Metric | Pearson Correlation |
|---|---|
| scoreq_ref | 0.867 |
| nomad | 0.826 |
| utmos | 0.823 |
| scoreq_nr | 0.809 |
| sheet_ssqa | 0.797 |
| audiobox_aesthetics_CE | 0.796 |
| audiobox_aesthetics_PQ | 0.795 |
| audiobox_aesthetics_CU | 0.777 |
Please note that only the metrics in bold will be used for the objective evaluation during the development phase. Nomad and scoreq_nr are not included as they are highly correlated with scoreq_ref. We exclude PQ and CU from audiobox_aesthetics metrics for the same reason. On top of the metrics listed above, PESQ is also included due to its relevance in assessing speech quality. No aggregate scores are computed for the objective evaluation. By default, the leaderboard entries are ranked in alphabetical order.
During the development phase, the (open test set)[https://github.com/cisco/multilingual-speech-testing/tree/main/LRAC-2025-test-data/open-test-set] will be used in combination with objective metrics to enable participants to benchmark their work in progress against other teams and analyze the strengths and weaknesses of their approach. The open test sets for the two challenge tracks consist of the following materials:
| Track | Data Type | Number of Files | Description |
| 1 | Clean | 600 | Clean speech files from various sources |
| 1 | Noisy | 200 | Speech in mild noise |
| 1 | Reverb | 200 | Speech in mild ambient noise and mild-to-moderate reverberation |
| 2 | Clean | 300 | Clean speech files from various sources |
| 2 | Noisy | 500 | Speech in mild, moderate, and strong noise |
| 2 | Reverb | 200 | Reververated speech; augmented using real-world RIRs |
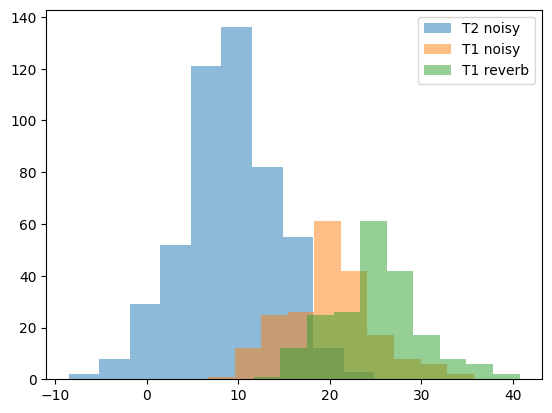
Figure 2: SNR distributions across open test subsets containing noise.
We aimed to tailor the open test sets to be approximately representative of the core test cases partipants will face in the blind test set evaluation. However, we would like to emphasize the following limitations (this list is not exhaustive):
- While the objective metrics may provide useful insights, objective metrics may under- or overestimate particularly generative systems.
- The metrics may not handle the presence of noise/reverb appropriately for Track 1. We provide results for the unprocessed files on the leaderboard for comparison, but caution participants to regard these scores as conclusive.
- No test cases are provided for intelligibility tests and simultaneous talkers. Participants may test simultaneous talker cases on their own files or simulate this case from the clean speech files. However, challenge participants must refrain from using the public word lists of the Diagnostic Rhyme Test as well as any previously published audio materials associated with this test to test and/or optimize their model.
- The meta files in the open test set subfolders contain SNR values for the data where noise and/or reverb augmentations were performed. Note that The SNR level corresponds to the crude overall ratio obtained from RMS dB levels of the speech and noise segments, respectively. As the RIRs used were real-world RIRs, internal estimates for DRR and RT60 were used to find the most appropriate test cases but are not provided for further analysis.
- The file durations, gender balance, SNR and reverb levels, as well as the noise types and their distributions were aimed to be as representative as possible with respect to the blind test set. However, as real-world data will be used for the blind set, differences due to estimation inaccuracies as well as source file availability are inevitable and should be anticipated.
- The numbers of files per subset were determined based on the approximate weighting in the final evaluation as well as the variety encountered in the respective scenario.
Subjective Evaluation
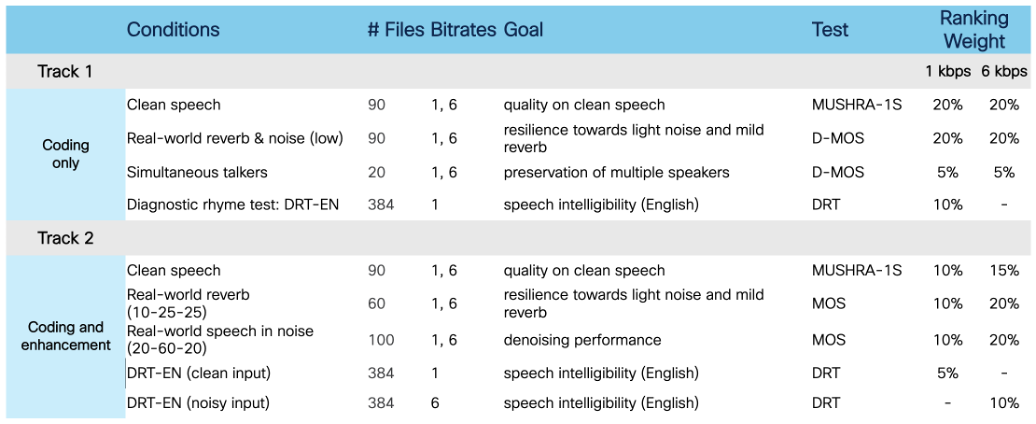 Figure 3: Neural Speech Codec Test Battery
Figure 3: Neural Speech Codec Test Battery
The subjective tests for both Challenge tracks are listed above, along with the corresponding test methods and weighting factors used to compute the overall submission rankings.
In Track 1, equal importance is given to the 1 kbps and 6 kbps conditions, as the input utterances are primarily clean or contain only mild reverberation and noise. An exception to this is the Diagnostic Rhyme Test (DRT), which assesses speech intelligibility. For Track 1, the DRT is conducted only at 1 kbps, based on the expectation that most systems will be fully intelligible at 6 kbps under clean conditions.
In Track 2, higher weights are assigned to the 6 kbps scores. This reflects the greater challenge of achieving good quality and intelligibility under high reverberation and low signal-to-noise ratio (SNR) conditions—particularly at very low bitrates. For the DRT in Track 2, testing is again limited to the clean condition at 1 kbps, as intelligibility is expected to plateau at 6 kbps. Given the anticipated poor intelligibility of 1 kbps systems in noisy conditions, the DRT will be assessed only at 6 kbps for noisy conditions.
Finally, the evaluation prioritizes performance in single-speaker scenarios over multi-speaker (overlapping) scenarios, as single-speaker speech is more prevalent in practical use cases. Moreover, reliably assessing quality in overlapping speech remains a complex and less mature area of evaluation. All evaluations will be performed exclusively on speech in the English language for this year’s challenge edition.
References
- [SIT.2024]
- L. Lechler and K. Wojcicki, “Crowdsourced Multilingual Speech Intelligibility Testing,” In Proc. ICASSP 2024, Seoul, South Korea, 2024, pp. 1441-1445.
- Manuscript: https://arxiv.org/pdf/2403.14817
- Public release of data and test software: https://github.com/cisco/multilingual-speech-testing/tree/main/speech-intelligibility-DRT
- [MUSHRA.2025]
- L. Lechler, C. Moradi and I. Balic, “Crowdsourcing MUSHRA Tests in the Age of Generative Speech Technologies: A Comparative Analysis of Subjective and Objective Testing Methods,” Interspeech 2025, Rotterdam, Netherlands (accepted, forthcoming).
- Manuscript: https://arxiv.org/pdf/2506.00950
- Public release of test data and softwware: in-preparation.