Datasets
Table of Contents
Training Datasets
Training datasets will include publicly available speech, noise and room impulse response datasets outlined in the tables below. Proposals for additional training dataset inclusions are encouraged from prospective participants until one week prior to challenge start.
Data preparation scripts are available in the data generation repository: https://lrac.short.gy/data-gen-repo.
Speech Datasets
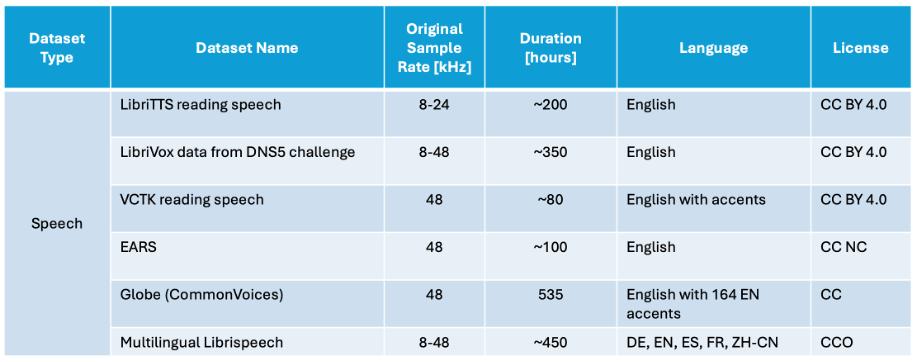
Figure 1: List of speech datasets permitted for model training in the 2025 LRAC Challenge.
The data preparation script by default applies filtering based on our analyses of estimations of SNR, reverberation metrics, and bandwidth. Additionally, we estimated speaker gender, speaker ID (where not available already), and per-speaker durations to achieve an approximately balanced and maximally diverse training set. Additionally, the filtering excludes files reserved for testing (open test set).
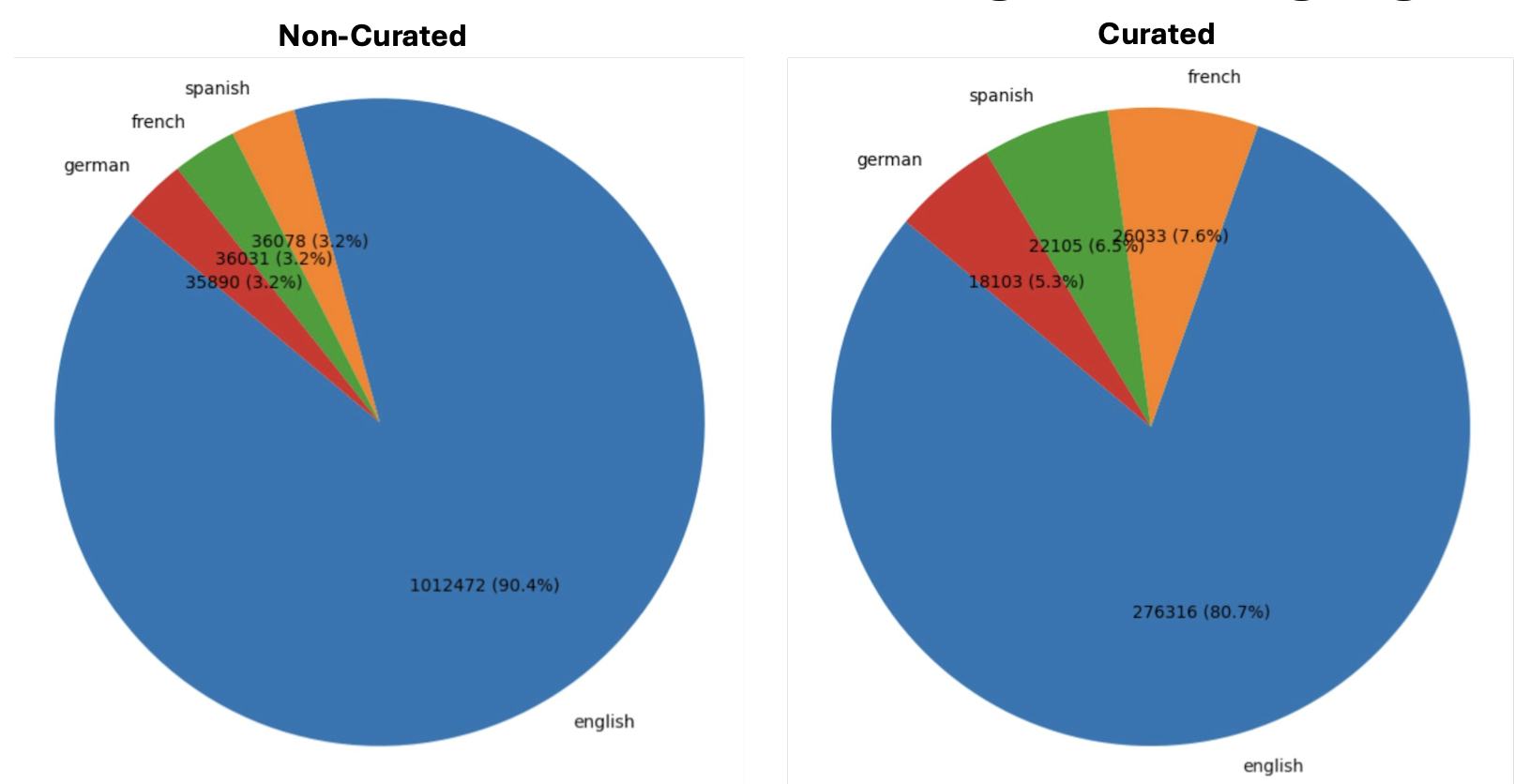
Figure 2: Number of files per Language for Non-Curated and Curated Training Data.
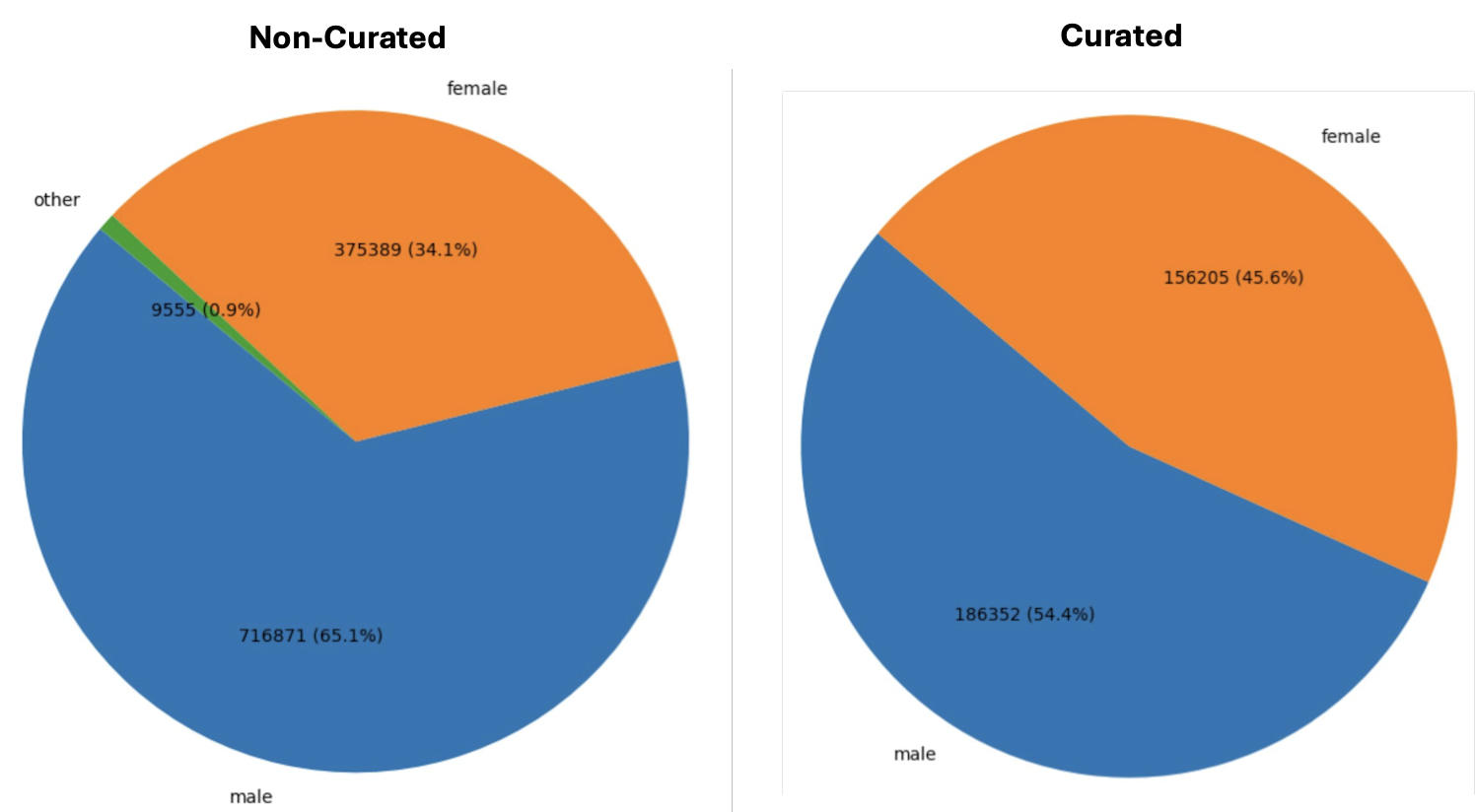
Figure 3: Gender Distribution for Non-Curated and Curated Training Data.
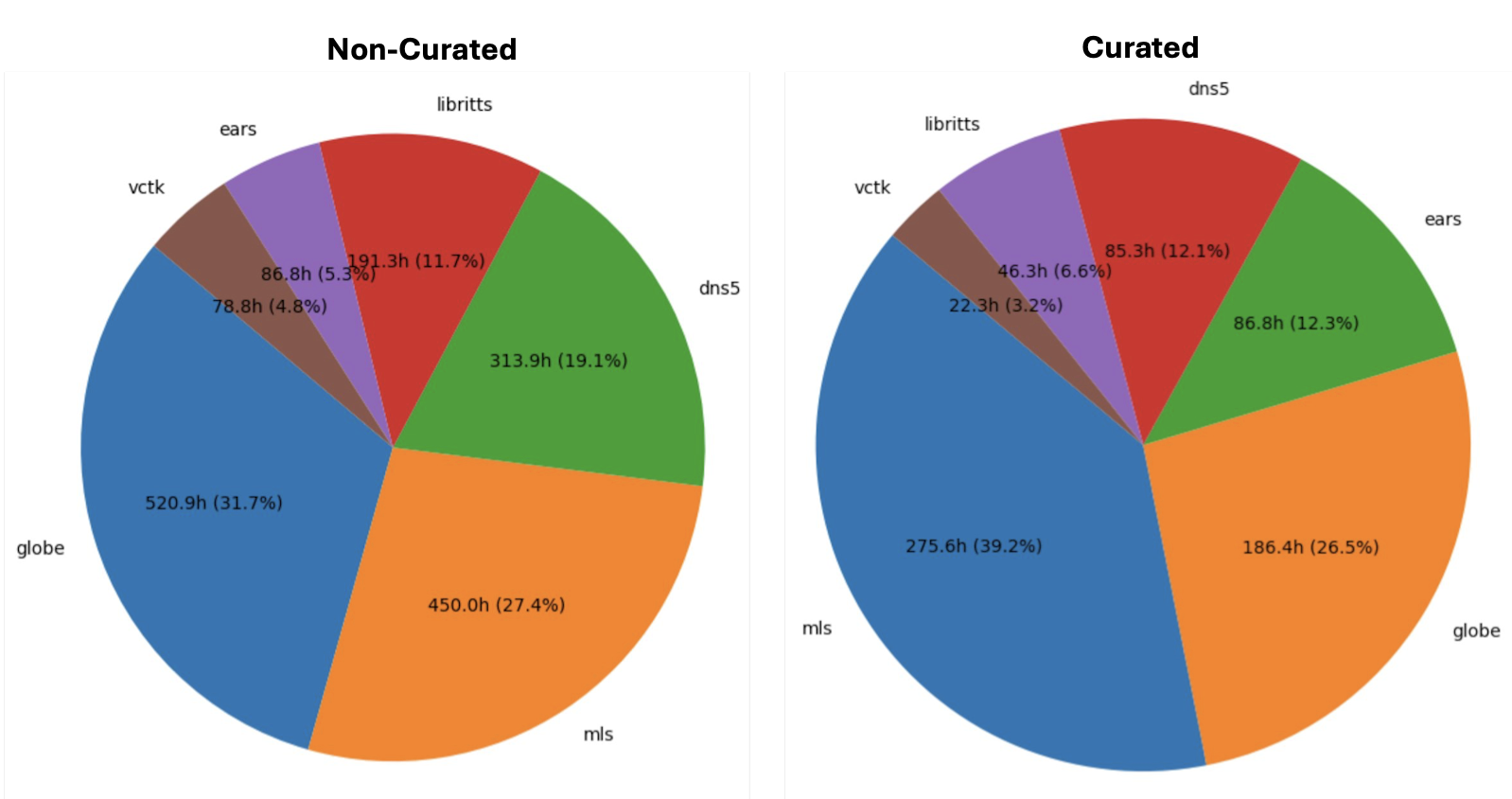
Figure 4: Number of hours per dataset for Non-Curated and Curated Training Data.
Noise Datasets
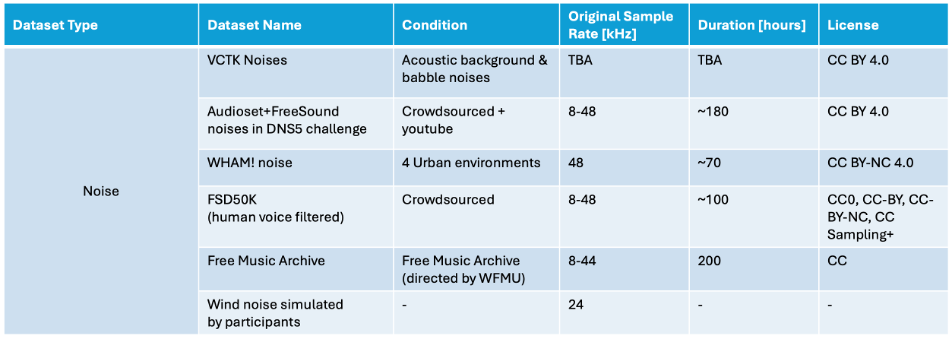
Figure 5: List of noise datasets permitted for model training in the 2025 LRAC Challenge.
From these datasets, we classify all files using an ontology that is rooted in Audioset, but trimmed down and emphasising broad noise categories and human vocal sounds. For classification, we use CLAP. In our own research using and modifying CLAP, we find that, on the dataset ESC-50 which has more classes but minimal class overlap, CLAP achieves an accuracy of 94.8%. On an internal dataset with a similar amount of classes but likely signifincalty more class overlap, CLAP achieves an accuracy of 62.3%. We expect the accuracy on these datasets to be somewhere in between these two numbers, likely towards the former as the classes we defiend for this task are more distinct than in the latter dataset.
We adjusted our class names to be ‘CLAP- friendly’. Figure 6 shows this distribution.
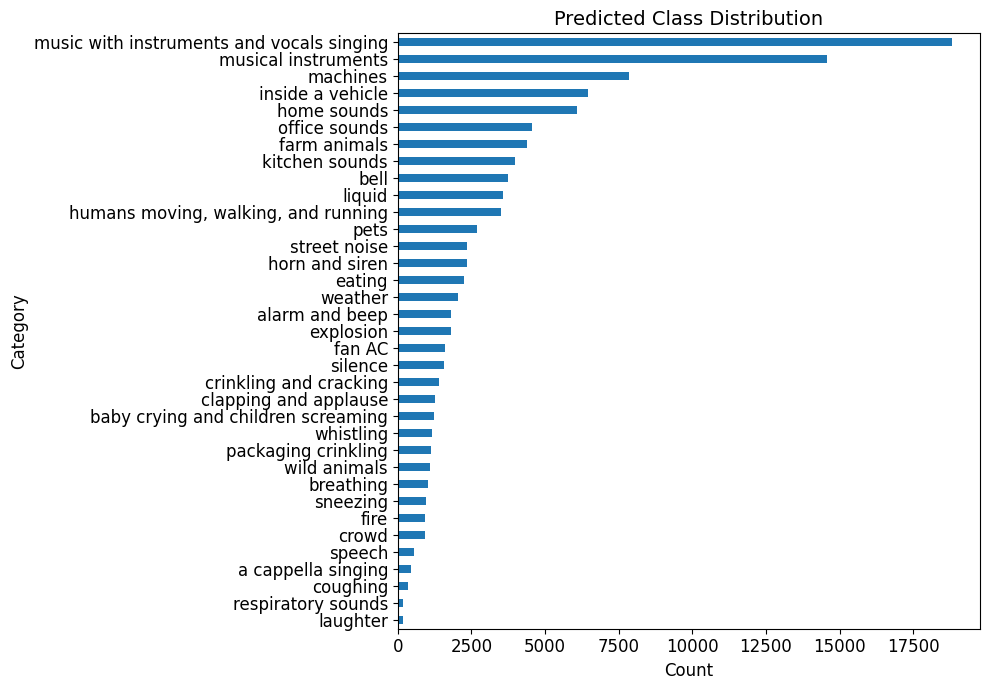
Figure 6: Full distribution of noises in the training noise dataset.
From that distribution, we derive a subset. We first remove the following classes ['music with instruments and vocals singing', 'speech', 'a cappella singing', 'laughter', 'silence'] which account for those classes that could be considered to have human vocal sounds, and silence. In addition, we take only the most probable 7500 files according to CLAP from 'musical instruments' and 'machines', in an effort to smooth out the distribution. Finally, we set aside a portion of the data for validation. The resulting final distribution of noises for the training set is shown in Figure 7.
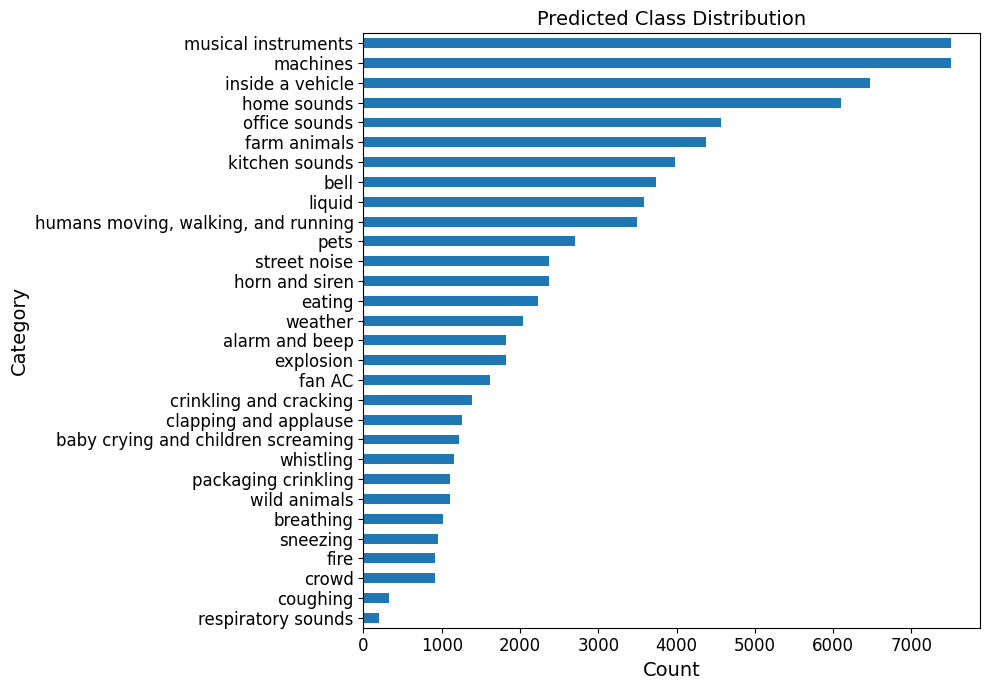
Figure 7: Final distribution of noises in the training noise dataset.
Room Impulse Response Datasets

Figure 6: List of room impulse response (RIR) datasets permitted for model training in the 2025 LRAC Challenge.